【ES三周年】深入理解 ELK 中 Logstash 的底层原理 + 填坑指南
本文目录如下:
 【资料图】
【资料图】
前言
通过本篇内容,你可以学到如何解决 Logstash 的常见问题、理解 Logstash 的运行机制、集群环境下如何部署 ELK Stack。
在使用 Logstash 遇到了很多坑,本篇也会讲解解决方案。
日志记录的格式复杂,正则表达式非常磨人。服务日志有多种格式,如何匹配。错误日志打印了堆栈信息,包含很多行,如何合并。日志记录行数过多(100 多行),被拆分到了其他的日志记录中。输出到 ES 的日志包含很多无意义字段。输出到 ES 的日志时间和本来的日志时间相差 8 小时。如何优化 Logstash 的性能Logstash 单点故障如何处理。一、部署架构图
上次我们聊到了 ELK Stack 的搭建:
一文带你搭建一套 ELK Stack 日志平台
最近悟空正在我们的测试环境部署这一套 ELK,发现还是有很多内容需要再单独拎几篇出来详细讲讲的,这次我会带着大家一起来看下 ELK 中的 Logstash 组件的落地玩法和踩坑之路。
测试环境目前有 12 台机器,其中 有 4 台给后端微服务、Filebeat、Logstash 使用,3 台给 ES 集群和 Kibana 使用。
部署拓扑图如下:
部署说明:
4 台服务器给业务微服务服务使用,微服务的日志会存放本机上。4 台服务器都安装 Filebeat 日志采集器,采集本机的微服务日志,其中一台服务器安装 Logstash ,Filebeat 发送日志给 Logstash。Logstash 将日志输出到 Elasticsearch 集群中。3 台服务器都安装有 Elasticsearch 服务,组成 ES 集群。其中一台安装 Kibana 服务,查询 ES 集群中的日志信息。二、Logstash 用来做什么?
你是否还在苦恼每次生产环境出现问题都需要远程到服务器查看日志文件?
你是否还在为了没有统一的日志搜索入口而烦心?
你是否还在为从几十万条日志中搜索关键信息而苦恼?
没错,Logstash 它来啦,带着所有的日志记录来啦。
Logstash 它是帮助我们收集、解析和转换日志的。作为 ELK 中的一员,发挥着很大的作用。
当然 Logstash 不仅仅用在收集日志方面,还可以收集其他内容,我们最熟悉的还是用在日志方面。
三、Logstash 的原理
3.1 从 Logstash 自带的配置说起
Logstash 的原理其实还比较简单,一个输入,一个输出,中间有个管道(不是必须的),这个管道用来收集、解析和转换日志的。如下图所示:
Logstash 组件
Logstash 运行时,会读取 Logstash 的配置文件,配置文件可以配置输入源、输出源、以及如何解析和转换的。
Logstash 配置项中有两个必需元素,输入(inputs)和输出(ouputs),以及一个可选元素 filters 过滤器插件。input 可以配置来源数据,过滤器插件在你指定时修改数据,output 将数据写入目标。
我们来看下 Logstash 软件自带的一个示例配置,文件路径:\logstash-7.6.2\config\logstash-sample.conf
是不是很简单,一个 input 和 一个 output 就搞定了。如下图所示:
但是这种配置其实意义不大,没有对日志进行解析,传到 ES 中的数据是原始数据,也就是一个 message 字段包含一整条日志信息,不便于根据字段搜索。
3.2 Input 插件
配置文件中 input 输入源指定了 beats,而 beats 是一个大家族,Filebeat 只是其中之一。对应的端口 port = 5044,表示 beats 插件可以往 5044 端口发送日志,logstash 可以接收到通过这个端口和 beats 插件通信。
在部署架构图中,input 输入源是 Filebeat,它专门监控日志的变化,然后将日志传给 Logstash。在早期,Logstash 是自己来采集的日志文件的。所以早期的日志检索方案才叫做 ELK,Elasticsearch + Logstash + Kibana,而现在加入了 Filebeat 后,这套日志检索方案属于 ELK Stack,不是 ELKF,摒弃了用首字母缩写来命名。
另外 input 其实有很多组件可以作为输入源,不限于 Filebeat,比如我们可以用 Kafka 作为输入源,将消息传给 Logstash。具体有哪些插件列表,可以参考这个 input 插件列表 1
3.3 Filter 插件
而对于 Logstash 的 Filter,这个才是 Logstash 最强大的地方。Filter 插件也非常多,我们常用到的 grok、date、mutate、mutiline 四个插件。
对于 filter 的各个插件执行流程,可以看下面这张图:
图片来自 Elasticsearch 官网
3.3.1 日志示例
我以我们后端服务打印的日志为例,看是如何用 filter 插件来解析和转换日志的。
logback.xml 配置的日志格式如下:
%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger - %msg%n 日志格式解释如下:
记录日志时间:%d{yyyy-MM-dd HH:mm:ss.SSS}记录是哪个线程打印的日志:%thread记录日志等级:%-5level打印日志的类:%logger记录具体日志信息:%msg%n,这个 msg 的内容就是 log.info("abc") 中的 abc。通过执行代码 log.info("xxx") 后,就会在本地的日志文件中追加一条日志。
3.3.2 打印的日志内容
从服务器拷贝出了一条日志,看下长什么样,有部分敏感信息我已经去掉了。
2022-06-16 15:50:00.070 [XNIO-1 task-1] INFO com.passjava.config - 方法名为:MemberController-,请求参数:{省略}那么 Logstash 如何针对上面的信息解析出对应的字段呢?比如如何解析出打印日志的时间、日志等级、日志信息?
3.3.3 grok 插件
这里就要用到 logstash 的 filter 中的 grok 插件。filebeat 发送给 logstash 的日志内容会放到 message 字段里面,logstash 匹配这个 message 字段就可以了。配置项如下所示:
filter { grok { match => [ "message", "(?\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s+\[(?.*)\]\s+(?\w*)\s{1,2}+(?\S*)\s+-\s+(?.*)\s*"] match => [ "message", "(?\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s{1,2}+(?\w*)\s{1,2}+.\s---+\s\[(?.*)\]+\s(?\S*)\s*:+\s(?.*)\s*"] }} 坑:日志记录的格式复杂,正则表达式非常磨人。
大家发现没,上面的 匹配 message 的正则表达式还是挺复杂的,这个是我一点一点试出来的。Kibana 自带 grok 的正则匹配的工具,路径如下:
http://:5601/app/kibana#/dev_tools/grokdebugger 我们把日志和正则表达式分别粘贴到上面的输入框,点击 Simulate 就可以测试是否能正确匹配和解析出日志字段。如下图所示:
Grok Debugger 工具
有没有常用的正则表达式呢?有的,logstash 官方也给了一些常用的常量来表达那些正则表达式,可以到这个 Github 地址查看有哪些常用的常量。
https://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/ecs-v1/grok-patterns比如可以用 IP 常量来代替正则表达式 IP (?:%{IPV6}|%{IPV4})。
好了,经过正则表达式的匹配之后,grok 插件会将日志解析成多个字段,然后将多个字段存到了 ES 中,这样我们可以在 ES 通过字段来搜索,也可以在 kibana 的 Discover 界面添加列表展示的字段。
坑:我们后端项目的不同服务打印了两种不同格式的日志,那这种如何匹配?
再加一个 match 就可以了。
filter { grok { match => [ "message", "(?\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s+\[(?.*)\]\s+(?\w*)\s{1,2}+(?\S*)\s+-\s+(?.*)\s*"] match => [ "message", "(?\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s{1,2}+(?\w*)\s{1,2}+.\s---+\s\[(?.*)\]+\s(?\S*)\s*:+\s(?.*)\s*"] }} 当任意一个 message 匹配上了这个正则,则 grok 执行完毕。假如还有第三种格式的 message,那么虽然 grok 没有匹配上,但是 message 也会输出到 ES,只是这条日志在 ES 中不会展示 logTime、level 等字段。
3.3.4 multiline 插件
还有一个坑的地方是错误日志一般都是很多行的,会把堆栈信息打印出来,当经过 logstash 解析后,每一行都会当做一条记录存放到 ES,那这种情况肯定是需要处理的。这里就需要使用 multiline 插件,对属于同一个条日志的记录进行拼接。
3.3.4.1 安装 multiline 插件
multiline 不是 logstash 自带的,需要单独进行安装。我们的环境是没有外网的,所以需要进行离线安装。
介绍在线和离线安装 multiline 的方式:
在线安装插件。在 logstash 根目录执行以下命令进行安装。
bin/logstash-plugin install logstash-filter-multiline在有网的机器上在线安装插件,然后打包。
bin/logstash-plugin install logstash-filter-multilinebin/logstash-plugin prepare-offline-pack logstash-filter-multiline拷贝到服务器,执行安装命令。
bin/logstash-plugin install file:///home/software/logstash-offline-plugins-7.6.2.zip安装插件需要等待 5 分钟左右的时间,控制台界面会被 hang 住,当出现 Install successful表示安装成功。
检查下插件是否安装成功,可以执行以下命令查看插件列表。当出现 multiline 插件时则表示安装成功。
bin/logstash-plugin list3.3.4.2 使用 multiline 插件
如果要对同一条日志的多行进行合并,你的思路是怎么样的?比如下面这两条异常日志,如何把文件中的 8 行日志合并成两条日志?
多行日志示例
思路是这样的:
第一步:每一条日志的第一行开头都是一个时间,可以用时间的正则表达式匹配到第一行。第二步:然后将后面每一行的日志与第一行合并。第三步:当遇到某一行的开头是可以匹配正则表达式的时间的,就停止第一条日志的合并,开始合并第二条日志。第四步:重复第二步和第三步按照这个思路,multiline 的配置如下:
filter { multiline { pattern => "^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}.\d{3}" negate => true what => "previous" }}时间的正则表达式就是这个 pattern 字段,大家可以根据自己项目中的日志的时间来定义正则表达式。
pattern: 这个是用来匹配文本的表达式,也可以是grok表达式what: 如果pattern匹配成功的话,那么匹配行是归属于上一个事件,还是归属于下一个事件。previous: 归属于上一个事件,向上合并。
next: 归属于下一个事件,向下合并
negate: 是否对 pattern 的结果取反false: 不取反,是默认值。
true: 取反。将多行事件扫描过程中的行匹配逻辑取反(如果 pattern 匹配失败,则认为当前行是多行事件的组成部分)
参考 multiline 官方文档 2
3.3.5 多行被拆分
坑:Java 堆栈日志太长了,有 100 多行,被拆分了两部分,一部分被合并到了原来的那一条日志中,另外一部分被合并到了不相关的日志中。
如下图所示,第二条日志有 100 多行,其中最后一行被错误地合并到了第三条日志中。
日志合并错乱
为了解决这个问题,我是通过配置 filebeat 的 multiline 插件来截断日志的。为什么不用 logstash 的 multiline 插件呢?因为在 filter 中使用 multiline 没有截断的配置项。filebeat 的 multiline 配置项如下:
multiline.type: patternmultiline.pattern: "^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}.\d{3}"multiline.negate: truemultiline.match: aftermultiline.max_lines: 50配置项说明:
multiline.pattern:希望匹配到的结果(正则表达式)multiline.negate:值为 true 或 false。使用 false 代表匹配到的行合并到上一行;使用 true 代表不匹配的行合并到上一行multiline.match:值为 after 或 before。after 代表合并到上一行的末尾;before 代表合并到下一行的开头multiline.max_lines:合并的最大行数,默认 500multiline.timeout:一次合并事件的超时时间,默认为 5s,防止合并消耗太多时间导致 filebeat 进程卡死我们重点关注 max_lines 属性,表示最多保留多少行后执行截断,这里配置 50 行。
注意:filebeat 和 logstash 我都配置了 multiline,没有验证过只配置 filebeat 的情况。参考 Filebeat 官方文档 3
3.3.6 mutate 插件
当我们将日志解析出来后,Logstash 自身会传一些不相关的字段到 ES 中,这些字段对我们排查线上问题帮助不大。可以直接剔除掉。
坑:输出到 ES 的日志包含很多无意义字段。
这里我们就要用到 mutate 插件了。它可以对字段进行转换,剔除等。
比如我的配置是这样的,对很多字段进行了剔除。
mutate { remove_field => ["agent","message","@version", "tags", "ecs", "input", "[log][offset]"]}注意:一定要把 log.offset 字段去掉,这个字段可能会包含很多无意义内容。
关于 Mutate 过滤器它有很多配置项可供选择,如下表格所示:
Mutate 过滤器配置选项
参考 Mutate 参考文章 4
3.3.7 date 插件
到 kibana 查询日志时,发现排序和过滤字段 @timestamp是 ES 插入日志的时间,而不是打印日志的时间。
这里我们就要用到 date插件了。
上面的 grok 插件已经成功解析出了打印日志的时间,赋值到了 logTime变量中,现在用 date 插件将 logTime匹配下,如果能匹配,则会赋值到 @timestamp字段,写入到 ES 中的 @timestamp字段就会和日志时间一致了。配置如下所示:
date { match => ["logTime", "MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601"]}但是经过测试写入到 ES 的 @timestamp日志时间和打印的日志时间相差 8 小时。如下图所示:
我们到 ES 中查询记录后,发现 @timestamp字段时间多了一个字母 Z,代表 UTC时间,也就是说 ES 中存的时间比日志记录的时间晚 8 个小时。
我们可以通过增加配置 timezone => "Asia/Shanghai" 来解决这个问题。修改后的配置如下所示:
date { match => ["logTime", "MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601"]}调整后,再加一条日志后查看结果,Kibana 显示 @timestamp 字段和日志的记录时间一致了。
3.4 Output 插件
Logstash 解析和转换后的日志最后输出到了 Elasticsearch 中,由于我们 ES 是集群部署的,所以需要配置多个 ES 节点地址。
output { stdout { } elasticsearch { hosts => ["10.2.1.64:9200","10.2.1.65:9200","10.27.2.1:9200"] index => "qa_log" }}注意这里的 index 名称 qa_log 必须是小写,不然写入 es 时会报错。
3.5 完整配置
logstah 配置文件内容如下:
input { beats { port => 9900 }}filter { multiline { pattern => "^\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2}.\d{3}" negate => true what => "previous" } grok { match => [ "message", "(?\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s+\[(?.*)\]\s+(?\w*)\s{1,2}+(?\S*)\s+-\s+(?.*)\s*"] match => [ "message", "(?\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2}.\d{3})\s{1,2}+(?\w*)\s{1,2}+.\s---+\s\[(?.*)\]+\s(?\S*)\s*:+\s(?.*)\s*"] match => [ "source", "/home/passjava/logs/(?\w+)/.*.log" ] overwrite => [ "source"] break_on_match => false } mutate { convert => { "bytes" => "integer" } remove_field => ["agent","message","@version", "tags", "ecs", "_score", "input", "[log][offset]"] } useragent { source => "user_agent" target => "useragent" } date { match => ["logTime", "MMM d HH:mm:ss", "MMM dd HH:mm:ss", "ISO8601"] timezone => "Asia/Shanghai" }}output { stdout { } elasticsearch { hosts => ["10.2.1.64:9200","10.2.1.65:9200","10.2.1.66:9200"] index => "qa_log" }} 四、Logstash 怎么跑起来的
4.1 Logstash 如何运行的
你会好奇 Logstash 是怎么运行起来的吗?
官方提供的启动方式是执行 logstash -f weblog.conf 命令来启动,当执行这个命令的时候其实会调用 Java 命令,以及设置 java 启动参数,然后传入了一个配置文件 weblog.conf 来启动 Logstash。
cd /home/logstash-7.6.2sudo ./bin/logstash -f weblog.conf当启动完之后,我们通过命令来看下 Logstash 的运行状态
ps -ef | grep logstash执行结果如下图所示,可以看到用到了 Java 命令,设置了 JVM 参数,用到了 Logstash 的 JAR 包,传入了参数。
所以建议 Logstash 单独部署到一台服务器上,避免服务器的资源被 Logstash 占用。
Logstash 默认的 JVM 配置是 -Xms1g -Xmx1g,表示分配的最小和最大堆内存大小为 1 G。
那么这个参数是在哪里配置的呢?全局搜索下 Xms1g,找到是在这个文件里面配置的,config\jvm.options,我们可以修改这里面的 JVM 配置。
我们可以调整 Logstash 的 JVM 启动参数,来优化 Logstash 的性能。
另外 Kibana 上面还可以监控 Logstash 的运行状态(不在本篇讨论范围)。
4.2 Logstash 的架构原理
本内容参考这篇 Logstash 架构 5
Logstash 有多个 input,每个 input 都会有自己的 codec。
数据会先存放到 Queue 中,Logstash 会把 Queue 中的数据分发到不同的 pipeline 中。
然后每一个 pipeline 由 Batcher、filter、output 组成
Batcher 的作用是批量地从 Queue 中取数据。Batcher 可以配置为一次取一百个数据。
五、Logstash 宕机风险
5.1 Logstash 单点部署的风险
因为 Logstash 是单点部署到一台服务器上,所以会存在两个风险:
logstash 突然崩了怎么办?logstash 所在的机器宕机了怎么办?Logstash 所在的机器重启了怎么办?对于第一个问题,可以安装 Keepalived 软件来保证高可用。另外即使没有安装,当手动启动 Logstash 后,Logstash 也能将未及时同步的日志写入到 ES。
对于第二个问题,所在的机器宕机了,那可以通过安装两套 Logstash,通过 keepalived 提供的虚拟 IP 功能,切换流量到另外一个 Logstash。关于如何使用 Keepalived,可以参考之前的 实战 MySQL 高可用架构
对于第三个问题,就是把启动 Logstash 的命令放到开机启动脚本中就可以了,但是存在以下问题:
Ubuntu 18.04 版本是没有开机启动文件的Logstash 无法找到 Java 运行环境接下来我们来看下怎么进行配置开机自启动 Logstash。
5.2 开机启动 Logstash
5.2.1 创建自动启动脚本
建立 rc-local.service 文件
sudo vim /etc/systemd/system/rc-local.service将下列内容复制进 rc-local.service 文件
[Unit]Description=/etc/rc.local CompatibilityConditionPathExists=/etc/rc.local [Service]Type=forkingExecStart=/etc/rc.local startTimeoutSec=0StandardOutput=ttyRemainAfterExit=yesSysVStartPriority=99 [Install]WantedBy=multi-user.target创建文件 rc.local
sudo vim /etc/rc.local添加启动脚本到启动文件中
#!/bin/sh -e# 启动 logstash#nohup /home/software/logstash-7.6.2/bin/logstash -f /home/software/logstash-7.6.2/weblog.conf &# 启动 filebeatnohup /home/software/filebeat-7.6.2-linux-x86_64/filebeat -e -c /home/software/filebeat-7.6.2-linux-x86_64/config.yml &exit 05.2.2 修改 Java 运行环境
因在开机启动中,logstash 找不到 java 的运行环境,所以需要手动配置下 logstash。
cd /home/software/logstash-7.6.2/bin/sudo vim logstash.lib.sh在 setup_java() 方法的第一行加入 JAVA_HOME 变量,JAVA_HOME 的路径需要根据自己的 java 安装目录来。
JAVA_HOME="/opt/java/jdk1.8.0_181"修改 Java 运行环境
5.2.3 权限问题
给 rc.local 加上权限, 启用服务
sudo chmod +x /etc/rc.localsudo systemctl enable rc-localsudo systemctl stop rc-local.servicesudo systemctl start rc-local.servicesudo systemctl status rc-local.serviceLogstash 启动成功
然后重启机器,查看 logstash 进程是否正在运行,看到一大串 java 运行的命令则表示 logstash 正在运行。
ps -ef | grep logstash六、总结
本篇讲解了 Logstash 在集群环境下的部署架构图、Logstash 遇到的几大坑、以及 Logstash 的运行机制和架构原理。
Logstash 还是非常强大的,有很多功能未在本篇进行讲解,本篇也是抛砖引玉,感兴趣的读者朋友们可以加我好友 passjava 共同探索。
更多好文请查看:
实战 MySQL 高可用架构
一文带你搭建一套 ELK Stack 日志平台
巨人的肩膀
https://blog.csdn.net/xzk9381/article/details/109571087https://www.elastic.co/guide/en/beats/filebeat/current/multiline-examples.htmlhttps://github.com/logstash-plugins/logstash-patterns-core/blob/main/patterns/ecs-v1/grok-patternshttps://www.runoob.com/regexp/regexp-syntax.htmlhttps://www.elastic.co/guide/en/beats/libbeat/current/config-file-permissions.htmlhttps://www.tutorialspoint.com/logstash/logstash_supported_outputs.htm参考资料
1input 插件列表: https://www.elastic.co/guide/en/logstash/current/input-plugins.html
2multiline 官方文档: https://www.elastic.co/guide/en/logstash/current/plugins-codecs-multiline.html#plugins-codecs-multiline-negate
3Filebeat 官方文档: https://www.elastic.co/guide/en/beats/filebeat/current/multiline-examples.html
4Mutate 参考文章: https://blog.csdn.net/UbuntuTouch/article/details/106466873
5Logstash 架构: https://jenrey.blog.csdn.net/article/details/107122930
END -上一篇:中泰证券:给予海尔智家买入评级
下一篇:最后一页
- 焦点消息!GPLP投融资:摩尔线程获15亿元 奔腾激光获1.7亿元
- 世界快消息!吃西瓜怎么保存不坏 西瓜怎么保存比较好
- 热点聚焦:一波N折 糖价明年有点看头
- 每日速递:声迅股份:发行可转债2.80亿元 申购日为12月30日
- 环球新动态:生意宝12月27日涨停分析
- 天天速读:日本强降雪致多人死伤 局地积雪厚度超1.6米
- 【世界播资讯】俄罗斯政府将拨款约15亿卢布用于国产飞机研发制造
- 环球百事通!最近头发老是掉,一抓一大把,这该怎么办呢?
- 当前聚焦:永清环保新余垃圾发电厂获2022年度新余市科技计划项目立项支持
- 当前热讯:调查:当年英国“脱欧”支持者中仅约三成认为“脱欧”成功
- 每日快讯!四位明星的家人因新冠去世!谢晋儿子抢救无效,樊登父亲安详离世
- 观速讯丨四高校花费超千万采购核酸检测服务,有供应商仅6人参保
- 每日快播:东方锆业“产能利用率”存疑:加码电熔氧化锆前景堪忧
- 【环球新要闻】重量天花板体验新标杆 OPPO Find N2上手评测
- 当前聚焦:新疆塔什库尔干机场正式通航 帕米尔高原喜迎“空中来客”
- 世界播报:大连合同纠纷律师收费标准
- 环球今头条!犀牛看市1220:大盘全天低开低走 汽车板块午后反弹
- 天天亮点!如何主动投资为插上量化翅膀?长盛基金王宁不喧哗自有声
- 当前关注:表面是百亿票房先生,实际全是“水货”,求求这几位演员别尬吹了
- 世界热门:上坤地产(06900.HK)再度大幅走强,尾盘升约45%
- 新动态:市场先生大变脸
- 快看点丨2023年初级会计师考试采取什么考试方式
- 全球快资讯:首钢股份董秘回复:长流程钢铁生产与短流程钢铁生产或是您提到的单工序生产都有各自的特点
- 今日关注:微软发现苹果 macOS 漏洞,可植入恶意软件
- 当前短讯!芳源股份: 独立董事关于第三届董事会第十二次会议相关事项的事前认可意见
- 每日速递:小鲨易贷逾期九年多久会上征信
- 焦点快报!【机构调研记录】长安基金调研浙海德曼
- 世界百事通!漳州龙海交警严查电动车非法加装挡风披
- 世界快看点丨犀牛宝逾期十二个月影响征信吗
- 全球聚焦:先行先试为企减负 反哺创新初显成效
- 全球热议:海航科技(600751):海航科技股份有限公司关于资产购买的进展公告
- 【快播报】2022年中国货车细分市场供需情况 轻型货车销量最高【组图】
- 天天视讯!【机构调研记录】金信基金调研福田汽车
- 全球热点评!辖区居民面包车被盗 濮阳华龙公安迅速出击
- 聚焦:尔康制药:对氨基苯酚目前满负荷生产
- 天天时讯:禾丰股份:12月14日融券卖出金额21.77万元,占当日流出金额的0.48%
- 今日最新!鑫铂股份(003038.SZ)1415.73万股限售股将于12月16日上市流通
- 环球热讯:西上海:如有重大事项,公司将依法依规进行信息披露
- 环球热点!12月13日基金净值:广发均衡增长混合A最新净值0.9697,跌0.26%
- 天天快播:黄山旅游(600054)12月13日主力资金净买入1515.54万元
- 【世界独家】南京化纤:截止2022年12月09日,公司股东人数为24223人
- 全球快看:斯迪克获3家机构调研:公司生产的OCA,应用场景非常广泛,除了应用在手机终端以外,还可以用在可穿戴设备等小尺寸的屏幕上(附调研问答)
- 天天通讯!沙棘的种植方法 沙棘树怎么种
- 重点聚焦!华通线缆: 河北华通线缆集团股份有限公司股东大会议事规则(2022年12月修订)
- 今热点:招商港口: 第十届董事会2022年度第十次临时会议决议公告
- 今日关注:南阳市镇平县:“五个一”开展网格化管理
- 世界信息:天沃科技董秘回复:感谢您对天沃科技的关心和支持!公司未开展虚拟电厂相关业务
- 深圳证券交易所2022年会员大会召开 提升服务实体经济能力
- 合肥举行“江淮普法行”活动 营造高质量法治环境
- 纸浆期货是否有效对冲废黄板纸现货价格波动风险?
-
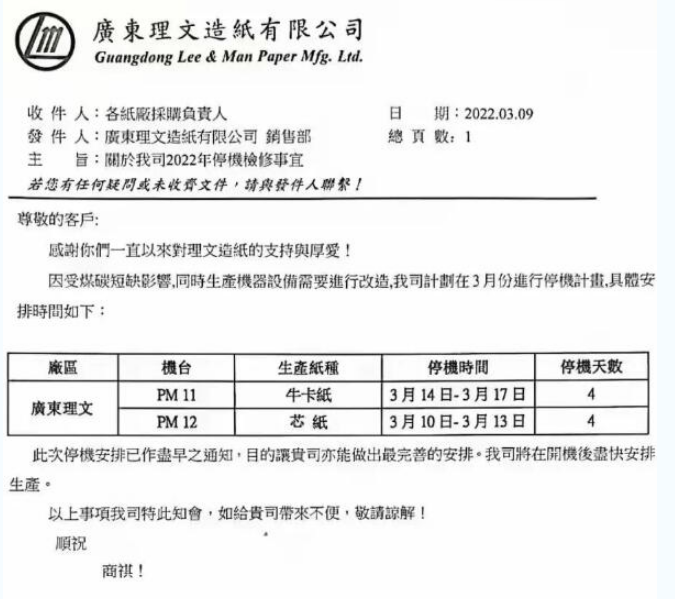
理文、山鹰发布停机函 包装纸市场涨价100-200元/吨
3月初,市场依然低迷!没想到即将步入中旬,市场却开始停机函、涨价函齐飞……这波操作会激起水花吗?3月9...
-

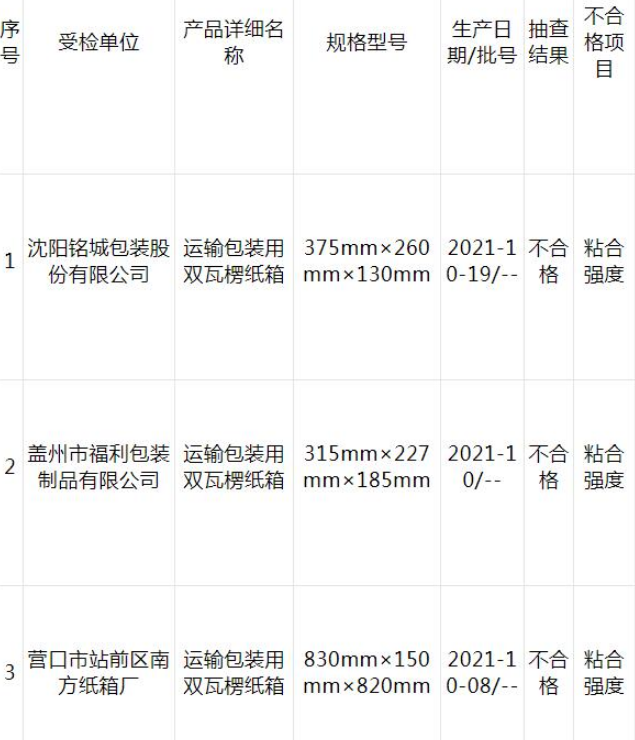
全部合格!广东珠海抽查5批次油墨产品
2021年第三季度,珠海市市场监督管理局组织开展了油墨产品质量监督抽查。本次共抽查了1家企业生产的5批...
-

浆系纸种再掀新一轮提价 涨幅达200-1500元/吨
继2月份多纸种接棒提价发起春季涨价攻势后,3月1日起,浆系纸种再掀新一轮的密集提价,涉及文化纸、白卡...
-

保定满城区开展纸制品行业专项检查 规范纸制品企业生产
为进一步规范纸制品企业生产经营行为,提升纸制品产业质量总体水平,近日,保定市满城区市场监督管理局...
-

2022年3月14日全国各地区纸厂废纸价格信息
华北地区:河北唐山乐亭张氏纸业,上调50元 吨。河北秦皇岛昌黎兴昌纸业,上调30元 吨。河北秦皇岛金...
-

包装材料、人工费等成本上升 台湾生活用纸涨价
由于原材料、物流、能源、环保以及包装材料、人工费等成本不断上升,台湾生活用纸生产企业已难以承受,...
-

上周木浆系纸品价格均有提涨 箱板纸价小幅下跌
本周轻工制造行业指数下跌4 57%, 跑输大盘0 35pct;造纸子板块下跌3 57%,跑赢大盘0 66pct 本周沪...
-

景兴纸业2021年营收同比增27.70% 净利同比增41.51%
3月14日,景兴纸业(002067)发布2021年度业绩快报公告,公告显示,2021年1-12月营业总收入为6,224,614,59...
-

1-2月全国快递业务收入1574.3亿 同比增长13.8%
3月14日,国家邮政局公布2022年2月邮政行业运行情况。数据显示,1-2月,全国快递服务企业业务量累计完成...
-

原料成本压力持续上升 浙江多家包装厂产品价格上涨3%
3月15日,多份包装企业涨价函从浙江嘉兴、湖州等地传来。在这些涨价函中,包装企业普遍表示,受疫情影响...
-

3月7日-13日生活用纸主要区域市场周度价格情况
上周(3月7—3月13日),河北、湖北、川渝、广西等生活用纸主要生产区域,纸浆及生活用纸市场价格情况汇总...
-

安徽出台“十四五”大气污染防治规划
安徽省生态环境厅日前印发《安徽省十四五大气污染防治规划》(以下简称《规划》)。《规划》要求,到2025...
-

原材料/燃料价格上涨 日本卫生纸、纸尿裤提价超10%
由于纸浆和能源等原材料 燃料价格上涨,物流成本、劳动力成本攀升以及环境措施成本增加,日本各造纸企...
-

新加坡超市将对塑料袋收费 至少5分新币/个
近日,永续发展与环境部长傅海燕在国会上宣布,从明年中旬起,三分之二新加坡超市都开始对一次性购物袋...
-
电子商务兴起 印度纸类包装行业发展趋势
随着市场越来越倾向于可持续性包装解决方案,预计未来几年对纸质包装的整体需求将增加。可持续性概念为...
-

2022年1-2月芬兰木材交易同比下滑20%
2022年1-2月,芬兰森林工业协会会员企业从私人森林采购木材累计达420万立方米,比去年同期下降20%。纸浆...
-

山东造纸行业深入实施“链长制”工作推进机制
造纸业作为基础原材料工业,在国民经济中占据重要地位。2021年,山东全省造纸行业深入实施链长制工作推...
-
包装原料价格波动再成热点 揭秘2021造纸上市企业业绩
近日,包装原料的价格波动再度成为热点,从废纸到原纸、到纸板,都传出了价格异动的消息。同时,在过去...
-

国家统计局:1-2月规上工业增加值同比实际增长7.5%
3月15日,国家统计局发布了2022年1-2月份工业生产主要数据。同日,国家统计局工业司副司长汤魏巍就1-2月...
-

2022年3月18日各地区各大纸厂废纸价格信息
华北地区:河北秦皇岛昌黎兴昌纸业,上调30元 吨。内蒙古昭宣纸业,下调20-30元 吨。华中地区:河南新...
-

江苏开展精准造林绿化 深入推进国土绿化和全民义务植树
江苏省今年着力实施精准绿化造林,深入推进国土绿化和全民义务植树。全省计划造林绿化20万亩,建设绿美...
-

正隆纸业员工返岗率超95% 预计今年营收同比增10%
人勤春来早,奋进正当时。位于厚街镇桥头第四工业区的正隆(广东)纸业有限公司(以下简称正隆纸业)自大年...
-

芬林芬宝劳马新锯材厂将启用自动装载生产线
芬林芬宝位于芬兰劳马的新锯材厂即将启用的自动装载生产线开创了锯材行业内的先河。自动装载指的是在无...
-

山东一小镇发展纸箱包装生产企业近百家 年产值11亿元
在山东省聊城市冠县北馆陶镇,返乡创业的孙凤湘在自家院子里把纸箱加工事业做得红红火火。他透露:从大...
-
打破性别“玻璃天花板” 95岁女院士是“她力量”最佳代言
鼓励女性打破“玻璃天花板” 95岁女院士就是“她力量”最佳代言 打破性别“玻璃天花板”,锤子...
-
河北辛集市暂停举办体育活动 关闭景区文娱场所
今天(11月8日)上午,河北省辛集市召开疫情防控新闻发布会,通报当地疫情防控最新情况。辛集市文体局...
-
红色文物·党史故事 “推出胜利”的小推车
“推出胜利”的小推车 李晓莉 在淮海战役纪念馆中,有一辆小推车格外引人注目,它就是淮海...
-
侵华日军南京大屠杀遇难同胞纪念馆闭馆
中新网南京11月8日电(记者 申冉)8日,侵华日军南京大屠杀遇难同胞纪念馆通报,该馆定于2021年11月1...
-
核酸采样:一位“点长”的50小时冲刺
11月4日晚上9点过,巴南区桥南社区盛世江南小区临时核酸采样点,市第七人民医院眼耳鼻喉科护士长张...
-
跑道结冰 哈尔滨机场关闭至9日12时
中新网哈尔滨11月8日电 (仇建 记者 史轶夫)哈尔滨太平国际机场8日发布消息,因跑道结冰,该机场...
-
北京地铁全面开启车内加热装置
地铁全面开启车内加热装置 本报讯(记者 李博)为做好降雪和强降温天气的应对工作,北京地铁合理...
-
黑河市多举措保障疫情期间残疾人等特殊群体生活稳定
中新网黑河11月8日电 (记者 史轶夫 王琳)8日,黑河市新冠肺炎疫情防控工作第十五场新闻发布会召...
-
北京丰台海淀两处管控区域解封 社区工作者收到“暖心礼物”
丰台海淀两处管控区域解封 居民和社区工作者收到“暖心礼物” 本报记者 孙颖 于丽爽 昨...
-
吉林四平一旅游项目违占耕地两千多亩 投资达10亿元
吉林四平一旅游项目违占两千多亩耕地被通报,投资达10亿元 近日,自然资源部通报了29宗农村乱占...
-
湖南双峰27名非法滞留缅北人员被惩戒:小孩回原籍入学
湖南双峰籍27名非法滞留缅北人员被惩戒:其小孩一律回原籍入学 为打击跨境电信诈骗犯罪,全国多...
-
江西新增本土“1+6” 上饶增一中风险地区
(抗击新冠肺炎)江西新增本土“1+6” 上饶增一中风险地区 中新网南昌11月8日电 (记者 吴鹏泉)...
-
江西上饶一地调整为中风险地区 实行封闭管理措施
中新网11月8日电 据江西省上饶市政府新闻办公室官方微博消息,上饶市新冠疫情防控应急指挥部8日发...
-
快递旺季遭遇雨雪天气 国家邮政局呼吁理解快递小哥
快递旺季遭遇雨雪天气 国家邮政局呼吁多理解和包容快递小哥 本报北京11月7日电(记者甘皙)国家...
-
高压、孤独,胆大、心细:手执焊枪的水下“蛙人”
高压、湿冷、孤独,胆大、心细、技艺高超—— 手执焊枪的水下“蛙人” 早上6时,伴随初升的朝...
-
掏粪掏了36年,他还在琢磨“新门道”
优化清掏路线、干活做到“三净”、总结技术诀窍,清掏工苏广林—— 掏粪掏了36年,他还在琢磨“...
-
内蒙古:二连浩特市新增1例本土确诊病例 额济纳旗累计治愈出院本土确诊病例76例
(抗击新冠肺炎)内蒙古:二连浩特市新增1例本土确诊病例 额济纳旗累计治愈出院本土确诊病例76例 ...
-
坚守在海拔4300多米的“天路保健医生”
中新网拉萨11月8日电(贡嘎来松)5日,青藏铁路格尔木至拉萨段达琼果站,海拔4327米。中铁十二局集团...
-
38年后,他终于知道了家在哪儿……
“我是谁,多大了,家在哪儿?”38年来,他总有这样一个心结被死死凝结,总为这样一句疑问而苦苦追...
-
受降雪影响 辽宁鞍山一农贸市场发生坍塌
8日早上6时左右,受连续强降雪影响,辽宁省鞍山市千山区大屯镇农贸市场发生坍塌,多台车辆被砸。 ...
-
中国舞蹈家协会顶尖教师巡回课堂(重庆站)举办
中新网北京11月8日电 (记者 高凯)由中国舞蹈家协会主办,中国文联舞蹈艺术中心、重庆市舞蹈家协会...
-
边城战“疫”:夜晚七点的暂停键
11月4日晚上7点,是中俄边境城市黑河一个再平凡不过的抗疫时刻。 如果在这一刻按下时间的暂停键...
-
风雪高原战“疫”长卷 寒潮下的西宁疫情防控观察
大风7级,大雪纷扬,最高气温只有-5℃! 这是青海省西宁市开启全城全员首轮核酸检测的天气。 ...
-
拟音师:“雕刻”声音的人【三百六十行】
三百六十行 拟音师:“雕刻”声音的人 闭上眼,90后赵洪泽有时甚至可以通过走路的声音,来判...
-
“双减”之后 中小学教师资格考试为何依然火爆
聚焦 “双减”之后,中小学教师资格考试为何依然火爆 近日,2021年下半年中小学教师资格考试(...
-
大数据助力贫困生成长
探索 大数据助力贫困生成长大数据画像能为贫困生成长带来什么 今年9月,云南省楚雄彝族自治州...
X 关闭





X 关闭